

CSIRO’s interoperability architects at Sparked have started critical work on how we share chronic care information far more seamlessly into the future and they genuinely want as much feedback from providers, patients and vendors as they can get.
In many respects the Sparked project being run by the CSIRO, which is aiming to lay a foundation for far more standardised and seamless sharing of healthcare data in Australia, is the most open, informed and inclusive national process that Australian digital health experts (possibly all health experts) have ever run.
The Sparked crew exude energy and enthusiasm and have done an amazing job of socialising what they are trying to do with the broader healthcare community to ensure they enrol as many providers, consumers, and tech vendors as they can into the process.
But in some ways the project feels like it might come across as secret squirrel to the vast majority of our healthcare community – it’s that technical, complex and difficult for your average provider, consumer and sometimes, even tech vendor, to get their heads around enough to meaningfully participate.
Past projects like Sparked have suffered from just how dense and technical the issues are in achieving digital interoperability across our vast array of healthcare software platforms, and hence have been largely driven by the experts, and the nerds.
The experts and the nerds are vital but without meaningful clinician, patient and software vendor input, projects in the past have gone significantly off the rails, at great expense sometimes to taxpayers.
If you review the list of participants in the vast array of workshops and the providers of feedback to Sparked so far, you will see significant external participation. It’s something the leaders at Sparked understand is vital to the process.
For any of those providers, consumers or vendors who aren’t participating yet, but have an interest, the work reached a pivotal point in the last few weeks: the group is down to the weeds of trying to understand how to best standardise data around chronic disease management for much better sharing.
The Sparked group has done a lot of foundation work to get here, including outlining the key framework for sharing a care summary, a patient summary and some initial thinking on chronic condition management sharing protocols.
But it’s now down to the key elements of chronic condition management protocols and as ever the group is asking for more and wider input – from existing interested parties and from anyone still out in the ether who sees anything obvious the group might want to think about in how they are framing their protocols for real life interoperability.
There is very clear evidence that an effective multidisciplinary approach to chronic care management could create massive system efficiencies and improvement in patient outcomes, but as things stand today in our system, chronic care management probably could not be more fragmented.
More seamless digital sharing of chronic care data through various software platforms used by overlapping chronic care teams has the potential to unleash a revolution in patient outcomes and system efficiency.
But the digital plumbing between our fragmented core systems – our GP PMS systems versus our many hospital EHR systems for example – needs significant smart thinking around how to get to a form of standardisation that will work across systems.
This is the work Sparked is up to over the next few months.
It might be the most important detail of all the work they have been doing to date.
At its core, this work is aiming to create standardised data groups that will help support care planning and chronic condition management.
Sparked has just released a draft of AUCDI Release 2 CCM (Australian Core Data Interoperability Release 2 Chronic Condition Management) containing proposed new data groups and data elements identified by the Sparked group as being important first steps “towards standardising data to support and enable information capture, exchange, and meaningful use across an individual’s health care and care team for chronic condition management”.
To get here workshops involving providers, patient advocates, government, tech vendors and informaticians were held by Sparked though the second half of 2024.
The figure below outlines the scope of the current data groups offered in AUCDI.
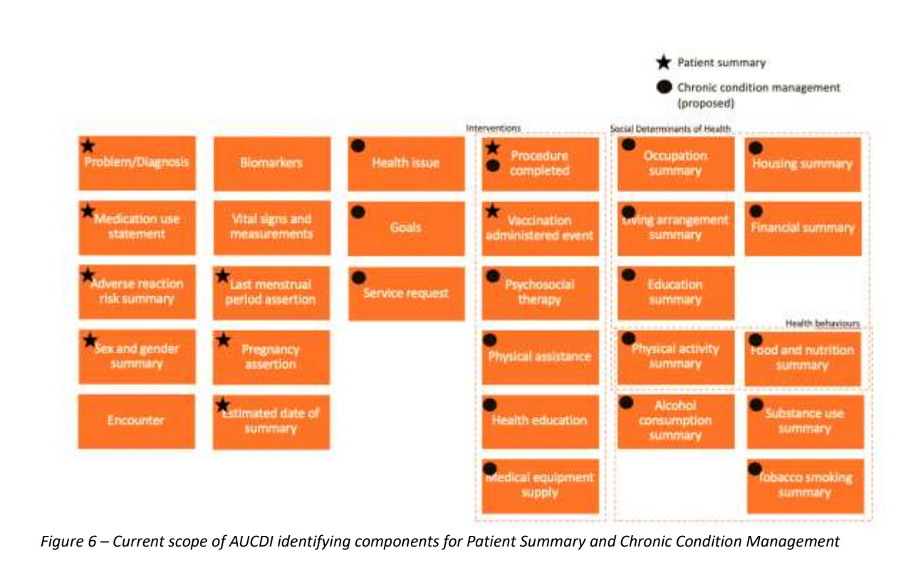
Data groups marked with a dot are anticipated for use within a Chronic Condition Management ecosystem, including a care plan.
Sparked is now seeking feedback and input on these data elements with a view to confirming they haven’t missed anything vital and that what they have is properly described so the coders won’t get anything wrong when it comes to making all this work on the cloud, significantly via the use of FHIR based interfaces.
Sparked points out that the way they are working is iterative and that at this point of time they want all the important basics down pat.
They expect that future enhancements to the data groups will evolve as clinical requirements for chronic condition management evolve and more detailed input is received on the core framework they establish.
If you want to join in on this fun venture or you’re already involved but you’ve missed the start on the work around chronic care, you’re starting point is probably HERE.
If you’re intrigued but completely new to AUCDI, Sparked and this vital healthcare system project it might be easier to start HERE.
Sparked do a great job on every document they publish of making sure anyone new knows what is going on and what you might be getting yourselves into.
But if you keep reading any of their documents, you’ll see just how much attention span you’re going to need to meaningfully keep up.